
Anwendungen, welche Machine Learning nutzen, benötigen in der Regel eine hohe Rechenleistung. Die Berechnungen finden normalerweise auf der GPU der Grafikkarte statt. Der Raspberry Pi ist nicht unbedingt dafür ausgelegt, rechenintensive Anwendungen auszuführen. Der Google Coral USB Accelerator schafft hier Hilfe! Mithilfe dieses Geräts können wir Echtzeit-Berechnungen wie Objekterkennung in Videos nutzen.
In diesem Tutorial schauen wir uns an, wie wir am Raspberry Pi Google Coral einbinden und nutzen können. Anschließend erstellen wir eine Live-Objekterkennung in einem Videostream von der Raspberry Pi Kamera.

Zubehör
In diesem Tutorial verwende ich folgendes Zubehör. Viele der Bauteile haben wir in vorherigen Tutorials bereits verwendet.
- Raspberry Pi
- Edge TPU: Google Coral USB Accelerator
- offizielles Raspberry Pi Kamera Modul
- alternativ: USB Webcam
- Einfache Objekte zur Erkennung (Bürogegenstände, Obst, etc.)
- optimal: Gehäuse mit Kühlern für den Pi und den USB Accelerator (kann auch 3D-gedruckt sein).

Wofür ist der Google Coral USB Accelerator zu gebrauchen?
Der Google Coral USB Accelerator enthält einen Prozesser, der für Berechnungen auf neuronalen Netzen spezialiert ist. Dieser Corprozessor wird Edge-TPU (Tensor Processing Unit) genannt.
Eine sehr gute Erklärung zu neuronalen Netzwerken, was diese genau sind und wieso man so häufig darüber im Zusammenhang mit Machine Learning ließt, gibt es in folgendem Video:
Eine der Hauptaufgaben ist also diese neuronalen Netze (in Form von Matrizen) zu lösen und das geht mit einer Edge TPU besonders gut. Damit wir von den Eigenschaften des Coral USB Accelerators profitieren können, stellt Google spezielle Bibliotheken bereit.
Google Coral Edge TPU Installation auf dem Raspberry Pi
Um die Rechenleistung der Coral Edge TPU nutzen zu können, müssen wir also ein paar Pakete installieren. Hierfür folgen wir überwiegend den Schritten der TPU Website. Öffne dazu ein Terminal (oder verbinde dich per SSH) und gib folgendes ein:
echo "deb https://packages.cloud.google.com/apt coral-edgetpu-stable main" | sudo tee /etc/apt/sources.list.d/coral-edgetpu.list curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add - sudo apt-get update
Danach können wir die Edge-TPU Runtime installieren:
sudo apt-get install libedgetpu1-std
Hinweis: Wenn du eine „schnellere“ Runtime (bedeutet: mit höherer Frequenz) installieren willst, nutze stattdessen diesen Befehl: sudo apt-get install libedgetpu1-max Beachte allerdings, dass du nicht beide Versionen gleichzeitig installiert haben darfst. Bei der höher frequentierten Variante wird die Betriebstemperatur außerdem steigen, weshalb du es nur bei ausreichend guter Kühlung nutzen solltest.
Nach der Installation kannst du den USB Accelerator an den Raspberry Pi anschließen (am besten an einem blauen USB 3.0 Port). Falls er bereits vor der Installation angeschlossen war, entferne ihn kurz und schließe ihn erneut an.
Jetzt installieren wir die Python-Pakete. Hierfür reicht folgender Befehl:
sudo apt-get install python3-pycoral --yes
TensorFlow Lite installieren
Wir werden außerdem natürlich TensorFlow Lite benötigen. Zunächst überprüfen wir die Version:
pip3 show tflite_runtime
Bei mir sieht das Ergebnis wie folgt aus:
Name: tflite-runtime Version: 2.5.0 Summary: TensorFlow Lite is for mobile and embedded devices. Home-page: https://www.tensorflow.org/lite/ Author: Google, LLC Author-email: packages@tensorflow.org License: Apache 2.0 Location: /usr/lib/python3/dist-packages Requires: Required-by: pycoral
Solltest du TensorFlow noch nicht installiert haben, kannst du das folgendermaßen nachholen und danach den Befehl noch einmal ausführen:
echo "deb https://packages.cloud.google.com/apt coral-edgetpu-stable main" | sudo tee /etc/apt/sources.list.d/coral-edgetpu.list curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add - sudo apt-get update sudo apt-get install python3-tflite-runtime
Objekterkennung in Videos mittels Google Coral und Raspberry Pi Kamera
Im Folgenden möchten wir die Objekterkennung live in einem Videostream aktivieren. Die Berechnungen laufen dabei auf der Edge-TPU. Um das Bild anzuzeigen, haben wir mehrere Möglichkeiten. Wir können z.B. Pakete wie PyGame, PiCamera oder OpenCV nutzen. Ich bevorzuge OpenCV, da wir damit noch viele weitere Funktionen aus dem Bereich Computer Vision nutzen können.
Zunächst verbinden wir die Raspberry Pi Kamera per CSI oder eine Webcam per USB. Die meisten Webcams werden automatisch erkannt.
Fangen wir also an mit einem Beispielprojekt. Öffne wieder das Terminal:
mkdir google-coral && cd google-coral git clone https://github.com/google-coral/examples-camera --depth 1
Im nächsten Schritt laden wir die vortrainierten Modelle. Du kannst stattdessen auch deine eigenen trainierten Modelle nutzen. In unserem einfachen Beispiel laden wir jedoch nur das MobileNet SSD300 Modell, welches bereits viele Objekte erkennen kann.
cd examples-camera sh download_models.sh
Der Vorgang dauert ein paar Minuten. Danach wechseln wir in den opencv-Ordner und installieren die Abhängigkeiten (falls du ein anderes Beispiel nutzen willst, hast du hier die Möglichkeit).
cd opencv bash install_requirements.sh
Nun können wir die Beispielanwendung starten. Du brauchst dafür eine Desktopumgebung. Falls du nicht direkt am Raspberry Pi arbeitest, empfehle ich eine Remotedesktop-Verbindung.
python3 detect.py
Dadurch öffnet sich ein neues Fenster mit dem Videostream. Darin werden erkannte Objekte jeweils mit Rechtecken markiert. Außerdem siehst du die berechnete Wahrscheinlichkeit (in Prozent), mit der das Objekt erkannt wurde (Wie wahrscheinlich es sich also um dieses Objekt handelt, laut Algorithmus).
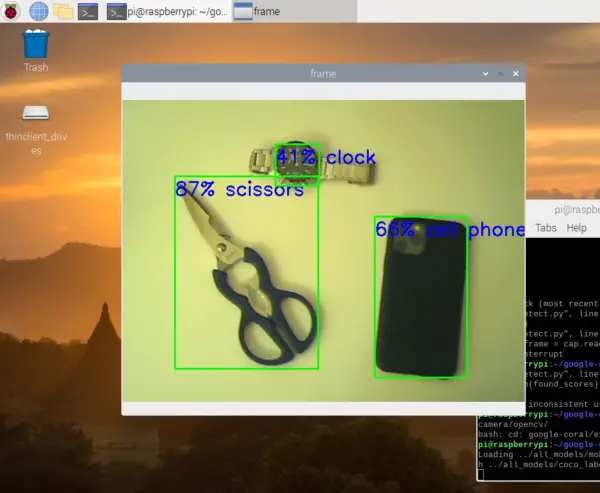
Schauen wir nun noch einmal genauer in den Code, um zu verstehen, was passiert:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 |
# Copyright 2019 Google LLC # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # https://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. """A demo that runs object detection on camera frames using OpenCV. TEST_DATA=../all_models Run face detection model: python3 detect.py \ --model ${TEST_DATA}/mobilenet_ssd_v2_face_quant_postprocess_edgetpu.tflite Run coco model: python3 detect.py \ --model ${TEST_DATA}/mobilenet_ssd_v2_coco_quant_postprocess_edgetpu.tflite \ --labels ${TEST_DATA}/coco_labels.txt """ import argparse import cv2 import os from pycoral.adapters.common import input_size from pycoral.adapters.detect import get_objects from pycoral.utils.dataset import read_label_file from pycoral.utils.edgetpu import make_interpreter from pycoral.utils.edgetpu import run_inference def main(): default_model_dir = '../all_models' default_model = 'mobilenet_ssd_v2_coco_quant_postprocess_edgetpu.tflite' default_labels = 'coco_labels.txt' parser = argparse.ArgumentParser() parser.add_argument('--model', help='.tflite model path', default=os.path.join(default_model_dir,default_model)) parser.add_argument('--labels', help='label file path', default=os.path.join(default_model_dir, default_labels)) parser.add_argument('--top_k', type=int, default=3, help='number of categories with highest score to display') parser.add_argument('--camera_idx', type=int, help='Index of which video source to use. ', default = 0) parser.add_argument('--threshold', type=float, default=0.1, help='classifier score threshold') args = parser.parse_args() print('Loading {} with {} labels.'.format(args.model, args.labels)) interpreter = make_interpreter(args.model) interpreter.allocate_tensors() labels = read_label_file(args.labels) inference_size = input_size(interpreter) cap = cv2.VideoCapture(args.camera_idx) while cap.isOpened(): ret, frame = cap.read() if not ret: break cv2_im = frame cv2_im_rgb = cv2.cvtColor(cv2_im, cv2.COLOR_BGR2RGB) cv2_im_rgb = cv2.resize(cv2_im_rgb, inference_size) run_inference(interpreter, cv2_im_rgb.tobytes()) objs = get_objects(interpreter, args.threshold)[:args.top_k] cv2_im = append_objs_to_img(cv2_im, inference_size, objs, labels) cv2.imshow('frame', cv2_im) if cv2.waitKey(1) & 0xFF == ord('q'): break cap.release() cv2.destroyAllWindows() def append_objs_to_img(cv2_im, inference_size, objs, labels): height, width, channels = cv2_im.shape scale_x, scale_y = width / inference_size[0], height / inference_size[1] for obj in objs: bbox = obj.bbox.scale(scale_x, scale_y) x0, y0 = int(bbox.xmin), int(bbox.ymin) x1, y1 = int(bbox.xmax), int(bbox.ymax) percent = int(100 * obj.score) label = '{}% {}'.format(percent, labels.get(obj.id, obj.id)) cv2_im = cv2.rectangle(cv2_im, (x0, y0), (x1, y1), (0, 255, 0), 2) cv2_im = cv2.putText(cv2_im, label, (x0, y0+30), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (255, 0, 0), 2) return cv2_im if __name__ == '__main__': main() |
- Zunächst einmal werden die benötigten PyCoral Bibliotheken eingebunden.
- In der main Funktion sind Argumente definiert, welche von der Kommandozeile übergeben werden können (Angabe des Modells usw.)
- Das Modell wird mit seinen Labels geladen und die Abmessungen anhand des Modells ermittelt (hier: 300×300)
- Anschließend wird der Videostream geöffnet (
cap = cv2.VideoCapture(args.camera_idx)) - Der interessante Teil passiert hier:
objs = get_objects(interpreter, args.threshold)[:args.top_k]
Dabei werden die 3 Elemente mit dem höchsten „Klassifizierungs-Score“ (über einem Schwellwert) ermittelt.
- Anschließend wird jedes erkannte Objekt auf dem Bild markiert.
Auf bestimmte Objekte reagieren
Was machen wir nun, wenn wir eine Aktion auslösen wollen, sobald ein bestimmtes Objekt erkannt wurde (z.B. eine Person)?
Dazu schauen wir uns zunächst einmal den Rückgabewert der get_objects Funktion an:
[ Object(id=16, score=0.5, bbox=BBox(xmin=-2, ymin=102, xmax=158, ymax=296)), Object(id=0, score=0.16015625, bbox=BBox(xmin=6, ymin=114, xmax=270, ymax=300)), Object(id=61, score=0.12109375, bbox=BBox(xmin=245, ymin=166, xmax=301, ymax=302)) ]
Wir sehen, dass jedes erkannte Objekt eine id, einen score und eine Bounding Box mit Koordinaten enthält. Um festzustellen, welches Objekt erkannt wurde, werfen wir einen Blick in die Labels:
{0: 'person', 1: 'bicycle', 2: 'car', 3: 'motorcycle', 4: 'airplane', 5: 'bus',
6: 'train', 7: 'truck', 8: 'boat', 9: 'traffic light', 10: 'fire hydrant', 1
2: 'stop sign', 13: 'parking meter', 14: 'bench', 15: 'bird', 16: 'cat', 17: 'dog',
18: 'horse', 19: 'sheep', 20: 'cow', 21: 'elephant', 22: 'bear', 23: 'zebra',
24: 'giraffe', 26: 'backpack', 27: 'umbrella', 30: 'handbag', 31: 'tie',
32: 'suitcase', 33: 'frisbee', 34: 'skis', 35: 'snowboard', 36: 'sports ball',
37: 'kite', 38: 'baseball bat', 39: 'baseball glove', 40: 'skateboard',
41: 'surfboard', 42: 'tennis racket', 43: 'bottle', 45: 'wine glass', 46: 'cup',
47: 'fork', 48: 'knife', 49: 'spoon', 50: 'bowl', 51: 'banana', 52: 'apple',
53: 'sandwich', 54: 'orange', 55: 'broccoli', 56: 'carrot', 57: 'hot dog',
58: 'pizza', 59: 'donut', 60: 'cake', 61: 'chair', 62: 'couch', 63: 'potted plant',
64: 'bed', 66: 'dining table', 69: 'toilet', 71: 'tv', 72: 'laptop', 73: 'mouse',
74: 'remote', 75: 'keyboard', 76: 'cell phone', 77: 'microwave', 78: 'oven',
79: 'toaster', 80: 'sink', 81: 'refrigerator', 83: 'book', 84: 'clock', 85: 'vase',
86: 'scissors', 87: 'teddy bear', 88: 'hair drier', 89: 'toothbrush'}
In meinem Fall wurden also die Objekte Cat (id=16), Person (id=0) und Chair (id=61) erkannt.
Falls du dich fragst, woher die ganzen Labels kommen: Diese wurden im Model trainiert und sind deshalb enthalten. Wenn du dein eigenes Model erstellst, kannst du auch nur ein einziges oder nur wenige Objekte inkludieren, welche für dich wichtig sind. Möglich wäre es auch z.B. sein eigenes Gesicht erkennen zu lassen.
Falls Interesse an einem Tutorial besteht, wie man so ein Model auf dem Raspberry Pi mit dem Google Coral USB Accelerator trainiert, würde ich mich über einen Kommentar freuen.
In dem genannten Beispiel wollen wir eine Aktion auslösen, sobald ein bestimmtes Objekt (bspw. ein Bus mit ID=5) erkannt wird. Dazu schauen wir zunächst die ID nach. Als Nächstes müssen wir prüfen, ob ein Objekt mit dieser ID gefunden wurde. Außerdem können wir noch einen Schwellwert (z.B. 0.8) für den Score einbauen. Der Pseudocode sähe so aus:
found_scores = [o.score for o in objs if o.id == 5] if len(found_scores) > 0 and max(found_scores) >= 0.8: # do something
Wie du siehst, ist das Reagieren darauf sehr einfach. Danach können wir z.B. das Foto speichern.
Fazit
Die Edge-TPU von Google bietet eine tolle Gelegenheit für alle, denen die Rechenkapazität des Raspberry Pi’s nicht ausreicht. Der USB Accelerator ist om Vergleich zu High-End Grafikkarten auch sehr günstig. Diese kosten schnell einmal über Tausend Euro.
Bei einer Auflösung von 300x300px läuft die Objekterkennung sehr flüssig. Auch eine höhere Auflösung ist möglich, jedoch musst du auf die Temperatur des Geräts achten. Ich empfehle für den Dauerbetrieb einen zusätzichen Lüfter.
Google bietet außerdem noch weitere Repositories mit Lerninhalten an. Für weitere Use-Cases mit dem Coral, ist dieses Repo noch interessant und u.a. mit Beispielen zur Bilderkennung ausgestattet.
Im Übrigen können wir auch unser eigenes Objekterkennungs-Modell mit TensorFlow erstellen. Hierfür müssen wir zunächst Bilder annotieren und anschließend ein Modell trainieren. Bei Interesse folgt dazu in Zukunft ein Tutorial.
Welche weiteren Machine-Learning-Anwendungen und Use Cases interessieren dich? Ich hatte über Projekte wie das automatische Erkennen von Nummernschildern und ähnlichem gedacht, aber bin gespannt auf weitere kreative Vorschläge für den Raspberry Pi mit Google Coral TPU.
11 Kommentare
Prima, vielen Dank! Und ja, ein einfaches TUT fürs Objekt-Training wäre wirklich spitze. (Habe mir dafür schon die Google Coral TPU zugelegt und unzählige Bilder gesammelt.)
Hallo,
kann man dafür auch den „GOOGLE CORAL DEV BOARD MINI “ verwenden?
Gruß
Stephan
Das mit dem trainieren eines eigenem Models wäre super spannend und hoch interessant. Bis jetzt hatte ich es noch nicht hinbekommen
Gruß
Vielen Dank.
Über ein Tutorial fürs Objekt-Training würde ich mich auch sehr freuen.
Danke! Genau das, was ich als Ansatz brauche! Unser kleiner Garten scheint von einer Katze als Katzenklo angesehen zu werden. Über eine entsprechende Installation könnte ich so Maßnahmen ergreifen, sie davon abzuhalten.
Bibliotheken mit Katzen gibt’s ja bestimmt schon. Vermutlich von Katzenbesitzern, die eher was anderes damit im Sinn haben, als bspw. Hundegebell abzuspielen.
Hallo,
ich habe gerade deinen Kommentar gelesen. Darf ich fragen, ob dein Projekt geklappt hat. Falls ja, könnten wir uns vielleicht über dein Projekt austauschen? Habe ein ähnliches Problem mit Tauben.
Gruss
Peter
Moin, sehr gut. Das, möglichst einfache, trainieren eigener Modelle wäre sehr spannend. VG
Hallo, tolles Tutorial.
Ich bekomme leider genau bei
objs = get_objects(interpreter, args.threshold)[:args.top_k] eine „list index out of range“ Exception. Es scheint am Interpreter zu liegen. Wie finde ich hier das Problem? Eine Idee?
Hallo, gute Tutorial, aber leider funktioniert das Skript install_requirements nicht mehr. Kannst du das fixen?
Looking in indexes: https://pypi.org/simple, https://www.piwheels.org/simple
ERROR: Could not find a version that satisfies the requirement opencv-contrib-python==4.1.0.25
ERROR: No matching distribution found for opencv-contrib-python==4.1.0.25
Danke
Kann ich damit auch die Schnecken in meinem Garten erkennen und am besten gleich sammeln?
Hi ich habe bei der Installation folgende Fehlermeldung bekommen:
sudo apt-get install python3-pycoral –yes
Paketlisten werden gelesen⦠Fertig
Abhängigkeitsbaum wird aufgebaut⦠Fertig
Statusinformationen werden eingelesen⦠Fertig
Einige Pakete konnten nicht installiert werden. Das kann bedeuten, dass
Sie eine unmögliche Situation angefordert haben oder, wenn Sie die
Unstable-Distribution verwenden, dass einige erforderliche Pakete noch
nicht erstellt wurden oder Incoming noch nicht verlassen haben.
Die folgenden Informationen helfen Ihnen vielleicht, die Situation zu lösen:
Die folgenden Pakete haben unerfüllte Abhängigkeiten:
python3-pycoral : Hängt ab von: python3-tflite-runtime (= 2.5.0.post1) soll aber nicht installiert werden
Hängt ab von: python3 (Paketlisten werden gelesen⦠Fertig
Abhängigkeitsbaum wird aufgebaut⦠Fertig
Statusinformationen werden eingelesen⦠Fertig
Einige Pakete konnten nicht installiert werden. Das kann bedeuten, dass
Sie eine unmögliche Situation angefordert haben oder, wenn Sie die
Unstable-Distribution verwenden, dass einige erforderliche Pakete noch
nicht erstellt wurden oder Incoming noch nicht verlassen haben.
Die folgenden Informationen helfen Ihnen vielleicht, die Situation zu lösen:
Die folgenden Pakete haben unerfüllte Abhängigkeiten:
python3-pycoral : Hängt ab von: python3-tflite-runtime (= 2.5.0.post1) soll aber nicht installiert werden
Hängt ab von: python3 (WARNING: Package(s) not found: tflite_runtime
wie kann ich die Probleme lösen ? vielen Dank für die Unterstützung. Im habe die Rasperian von Nov24 auf Raspi 4 installiert.